1 Institute of Neuroinformatics, University of Zürich and ETH Zürich, Zürich, Switzerland
2 Department of Electronics and Nanoengineering, School of Electrical Engineering, Aalto University, Espoo, Finland
3 Department of Microelectronics, Delft University of Technology, Delft, The Netherlands
4 Leiden Institute of Advanced Computer Science (LIACS), Leiden University, Leiden, The Netherlands
* Equal contribution
Introducing FENNEC
FENNEC (Feature Extractor with Neural Network for Efficient speech Comprehension) is an ultra-low-power bionic system-on-chip (SoC) that enables always-on voice user interface for extreme edge devices, e.g., earbuds, smart rings and wireless sensor nodes. With a cochlea-inspired analog frontend and a brain-inspired digital backend, FENNEC performs end-to-end audio-to-intent classification in real-time, with only <10μW power and a tiny 3mm2 footprint. This post summarizes the design of FENNEC, which has been published in the top integrated circuit design conference ISSCC and journal JSSC.
Fennec is the name of a small fox living in the desert of North Africa. Its most distinctive feature is its unusually large ears to listen for underground prey and to dissipate heat, shown in the figure below.
 A fennec fox.
A fennec fox.
Background
Voice user interface provides hands-free user interaction for tiny Internet of Things (IoT) nodes and wearable devices, but their limited power budget poses a challenge, requiring bespoke ultra-low-power integrated circuit (IC) design. Prior designs focused on voice activity detection (VAD) or keyword spotting (KWS), with relatively short context and small number of classes. FENNEC addresses a more challenging task known as spoken language understanding (SLU), with longer context and more classes.
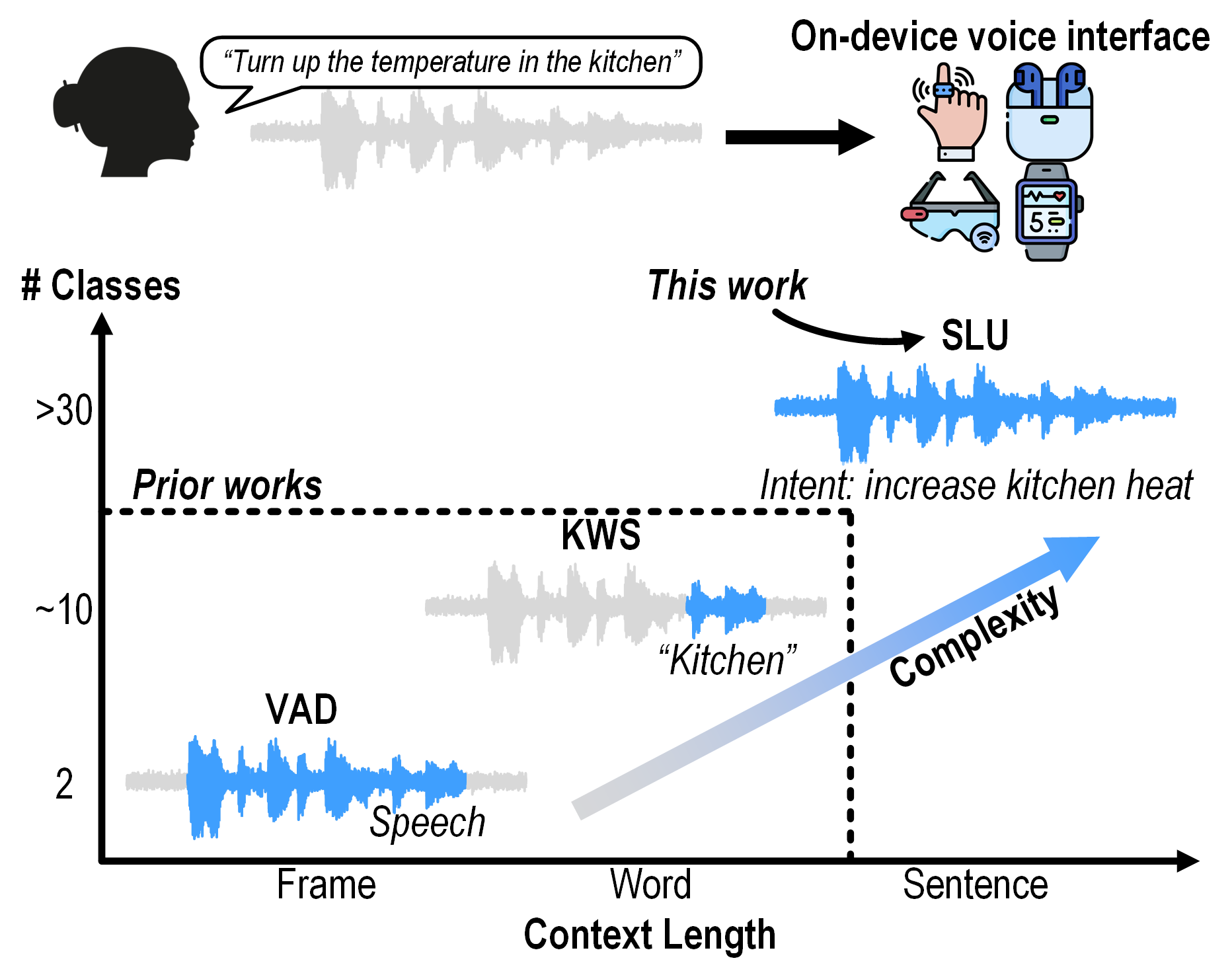 Different audio classification tasks for voice interface on the extreme edge:
Different audio classification tasks for voice interface on the extreme edge:
voice activity detection (VAD), keyword spotting (KWS), and spoken language understanding (SLU).
An end-to-end SLU system infers user intent directly from continuous spoken sentences. The table below shows some example sentences and their corresponding user intents from the Fluent Speech Commands Dataset (FSCD), a public dataset for training and evaluating SLU systems.
| Sentence | Intent |
|---|---|
| 🔊 Turn the bedroom heat up |
Action: increase Object: heat Location: bedroom |
| 🔊 OK now switch the main language to Chinese |
Action: change language Object: Chinese Location: none |
| 🔊 Increase the temperature in the washroom |
Action: increase Object: heat Location: washroom |
| 🔊 Turn off the kitchen lights |
Action: deactivate Object: lights Location: kitchen |
| 🔊 Could you increase the heating? |
Action: increase Object: heat Location: none |
Our design
On-device SLU involves three stages: a microphone, an acoustic feature extractor (FEx), and a deep neural network (DNN). To minimize power consumption, FENNEC employs three major innovations to reduce power without compromising SLU performance: automatic gain control, hardware-aware training, and temporal-sparsity-aware compute.
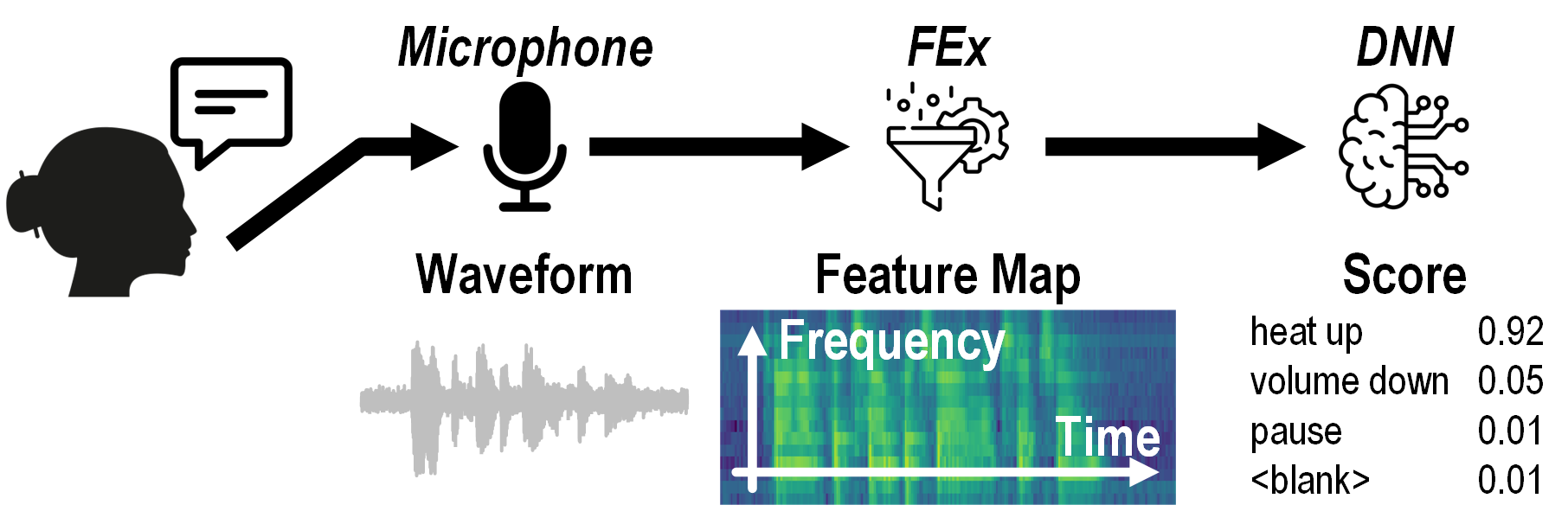 The three stages of SLU:
microphone, feature extractor (FEx), and deep neural network (DNN).
The three stages of SLU:
microphone, feature extractor (FEx), and deep neural network (DNN).
Automatic gain control (AGC)
Real-world speech has a large dynamic range (DR). This is challenging for the on-chip analog frontend (AFE) because large signals could be clipped and small signals could be undetectable. Automatic gain control (AGC) solves the challenge by dynamically lowering the gain for large inputs and increasing the gain for small inputs, effectively normalizing the signal energy in real-time.
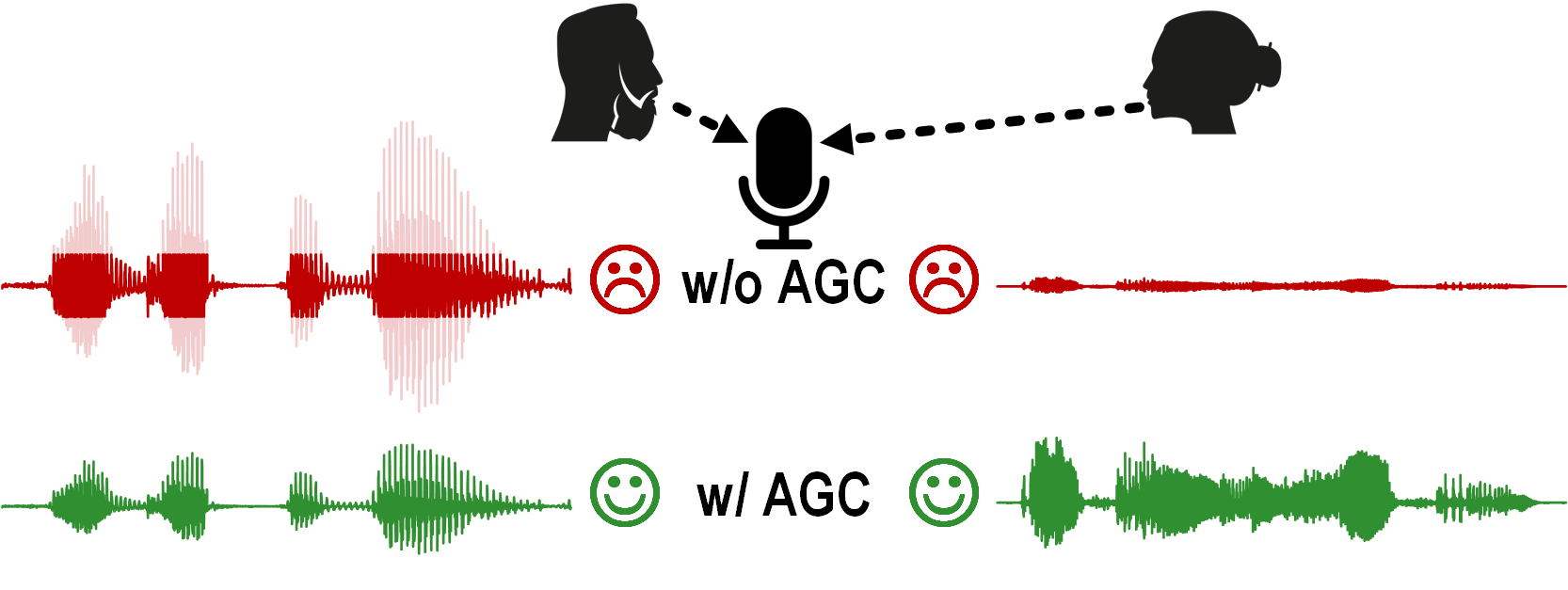 Automatic gain control (AGC) is crucial for real-world speech,
which have wide dynamic range (DR)
Automatic gain control (AGC) is crucial for real-world speech,
which have wide dynamic range (DR)
due to variation in speech volume and speaker distance.
Rather than using a power-hungry Nyquist-rate ADC, FENNEC’s AFE is inspired by the cochlea, which is a remarkably power efficient FEx with direct analog-to-feature conversion and >120dB DR. Human hearing involves two types of AGC: global (frequency-agnostic) AGC by the acoustic reflex of the middle ear, and local (frequency-dependent) AGC by the active amplification of the outer hair cells within the cochlea. Shown in the diagram below, FENNEC’s AFE implements both global and local AGC to maximize its DR.
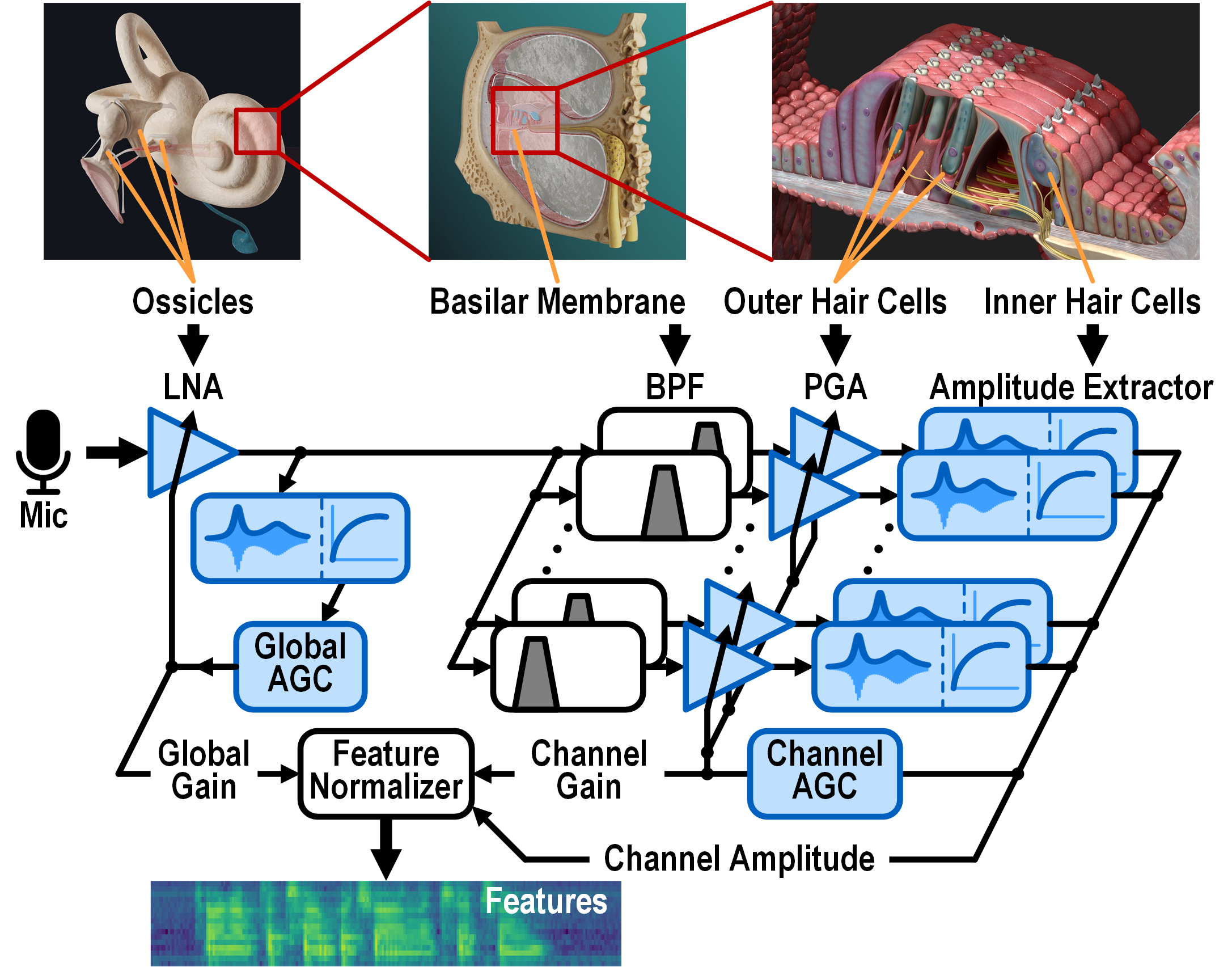 Inspired by the biological cochlea, FENNEC’s feature extractor incorporates
Inspired by the biological cochlea, FENNEC’s feature extractor incorporates
both global and per-frequency-channel local AGC.
Hardware-aware training (HAT)
To make informed decisions when designing a complex analog system like FENNEC’s AFE, it is essential to have a fast and accurate simulator. Transistor-level Spectre simulation provides gold-standard accuracy but is far too slow, taking 51h for a 3s-long audio input. Instead, our custom behavioral model in Python generates features well aligned with Spectre (cosine similarity > 0.98), but five orders of magnitude faster.
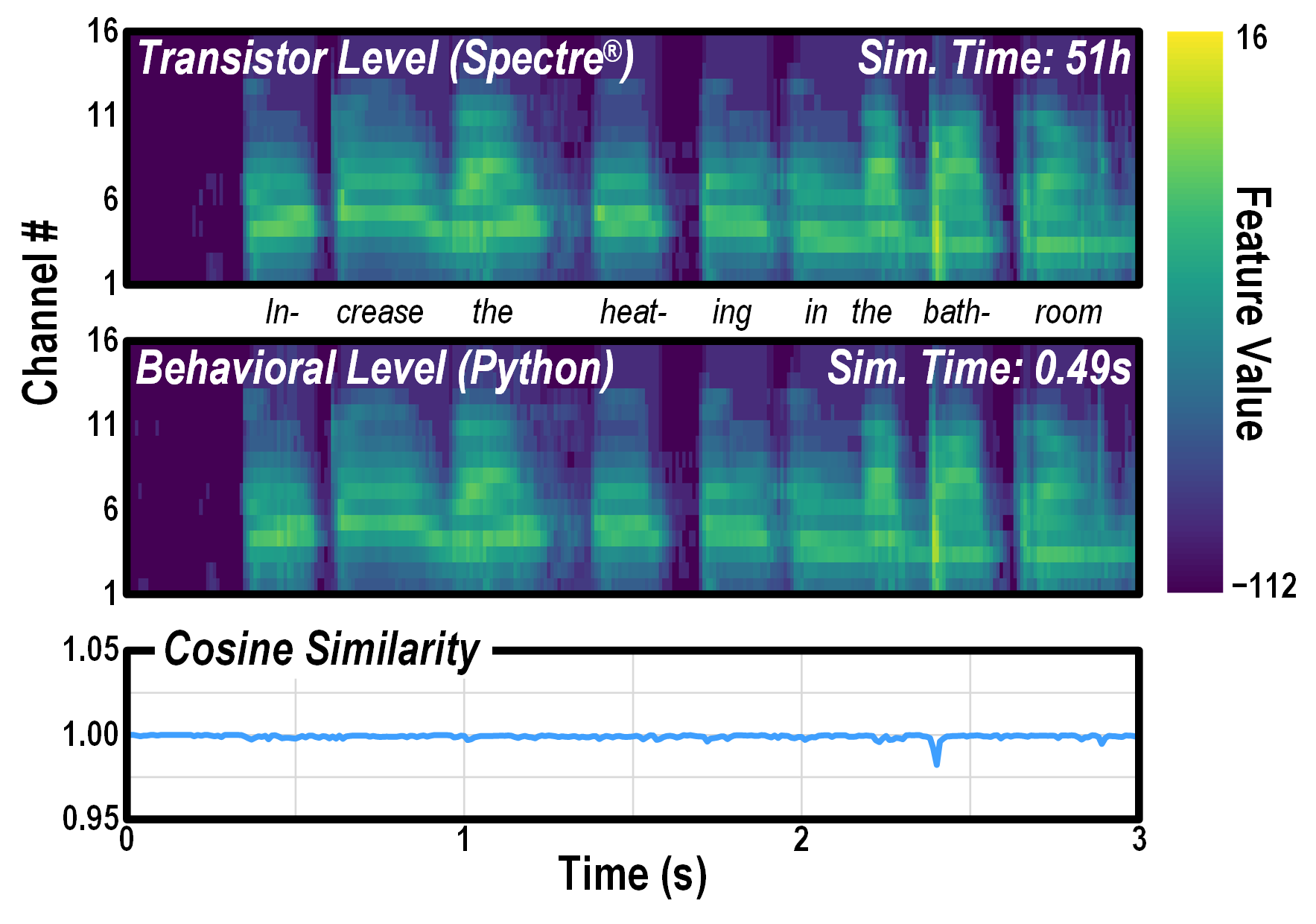 Our custom Python behavioral model generates features well aligned with Spectre,
but much faster.
Our custom Python behavioral model generates features well aligned with Spectre,
but much faster.
Analog FEx is prone to nonidealities such as noise and mismatch, reducing the downstream SLU accuracy. To prevent this, FENNEC uses hardware-aware training (HAT). When generating training features, the Python model includes nonidealities extracted from Spectre simulation, allowing the network to compensate the accuracy drop. The AFE design is iteratively optimized to meet the power and accuracy requirements.
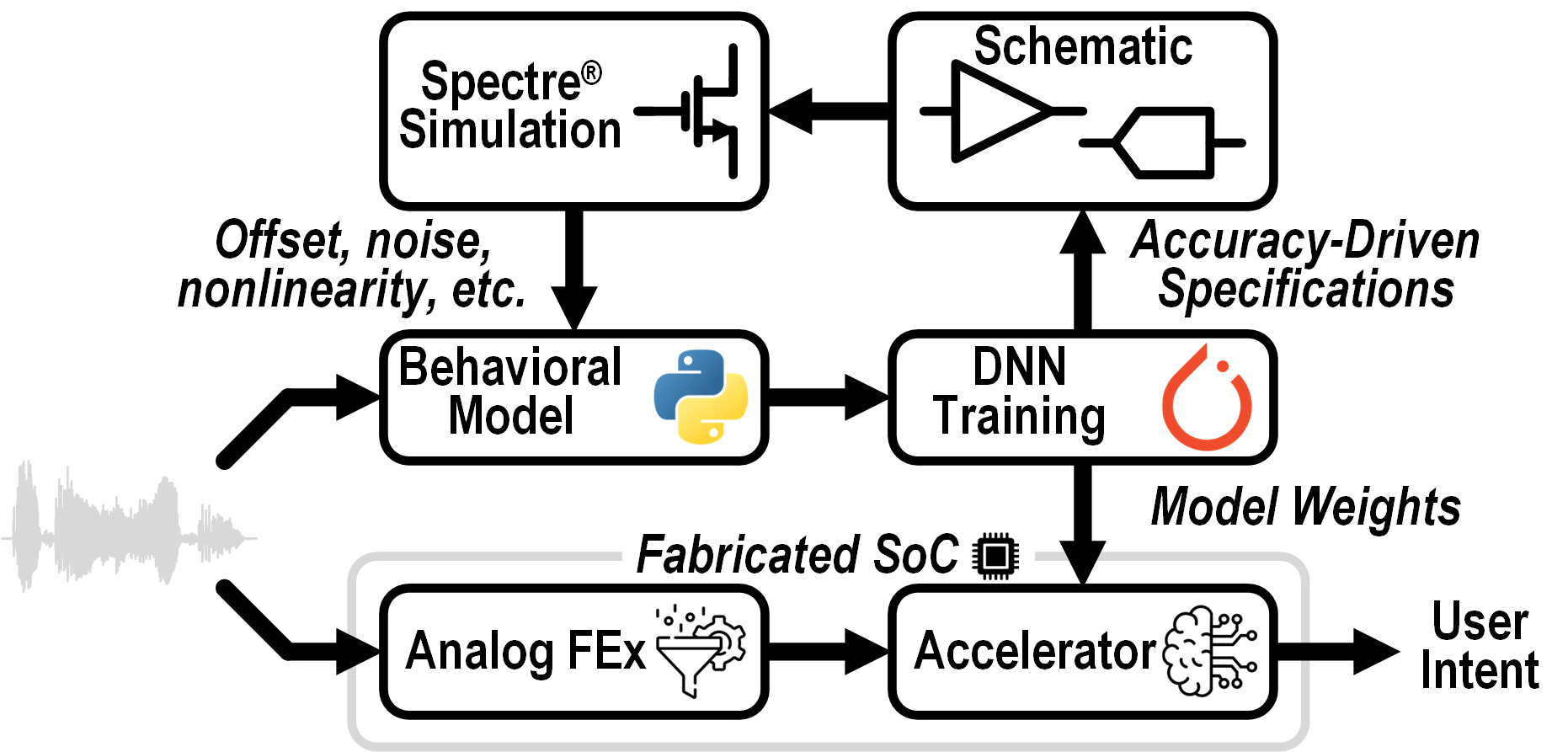 Hardware-aware training (HAT) workflow employed by FENNEC.
Hardware-aware training (HAT) workflow employed by FENNEC.
It improves neural network robustness while avoiding circuit overdesign and energy waste.
Temporal sparsity (Δ-GRU)
For the digital backend (DBE), FENNEC uses a gated recurrent unit (GRU) network for its efficient processing of long sequences like speech. While vanilla GRU has limited activation sparsity, FENNEC uses a variant called Δ-GRU. It exploits the similarity between adjacent feature/activation frames by processing the Δ-activations, which exhibits high temporal sparsity for natural signals. Its computational pattern resembles the dynamically sparse processing seen in the biological brain. FENNEC’s DBE further combines temporal sparsity with temporal pooling to cut the power by 2.3×.
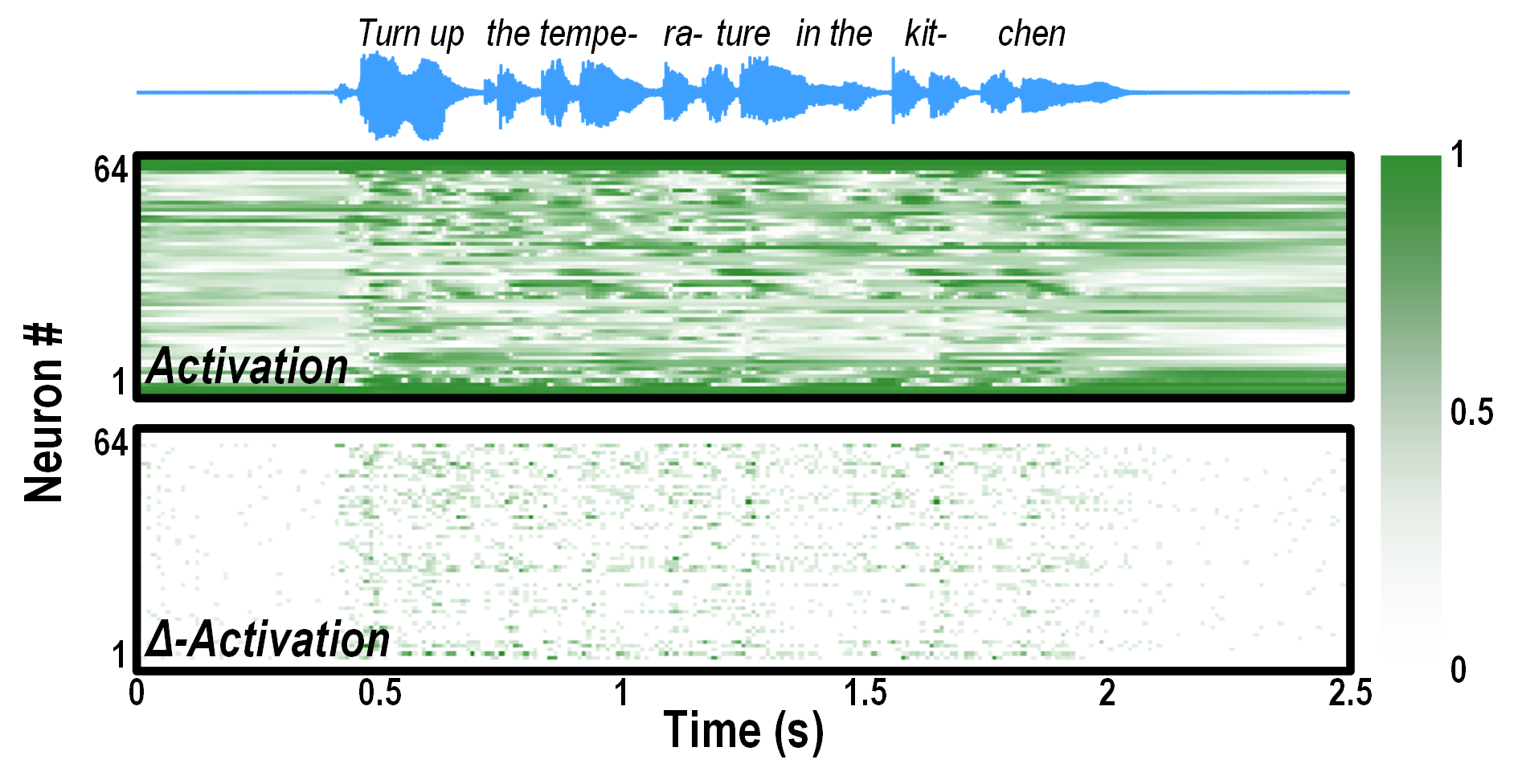 Dense activations of a vanilla GRU versus sparse Δ-activations of a Δ-GRU (Python simulation).
Dense activations of a vanilla GRU versus sparse Δ-activations of a Δ-GRU (Python simulation).
Results
FENNEC is implemented in a 65nm CMOS process with a core area of 2.23mm2. Its building blocks are annotated in the chip micrograph below. We use FENNEC to build a standalone SLU system powered by a CR2450 coin battery. The SLU system is in the size of a credit card, and using more compact packaging could further reduce its size to mm-scale.
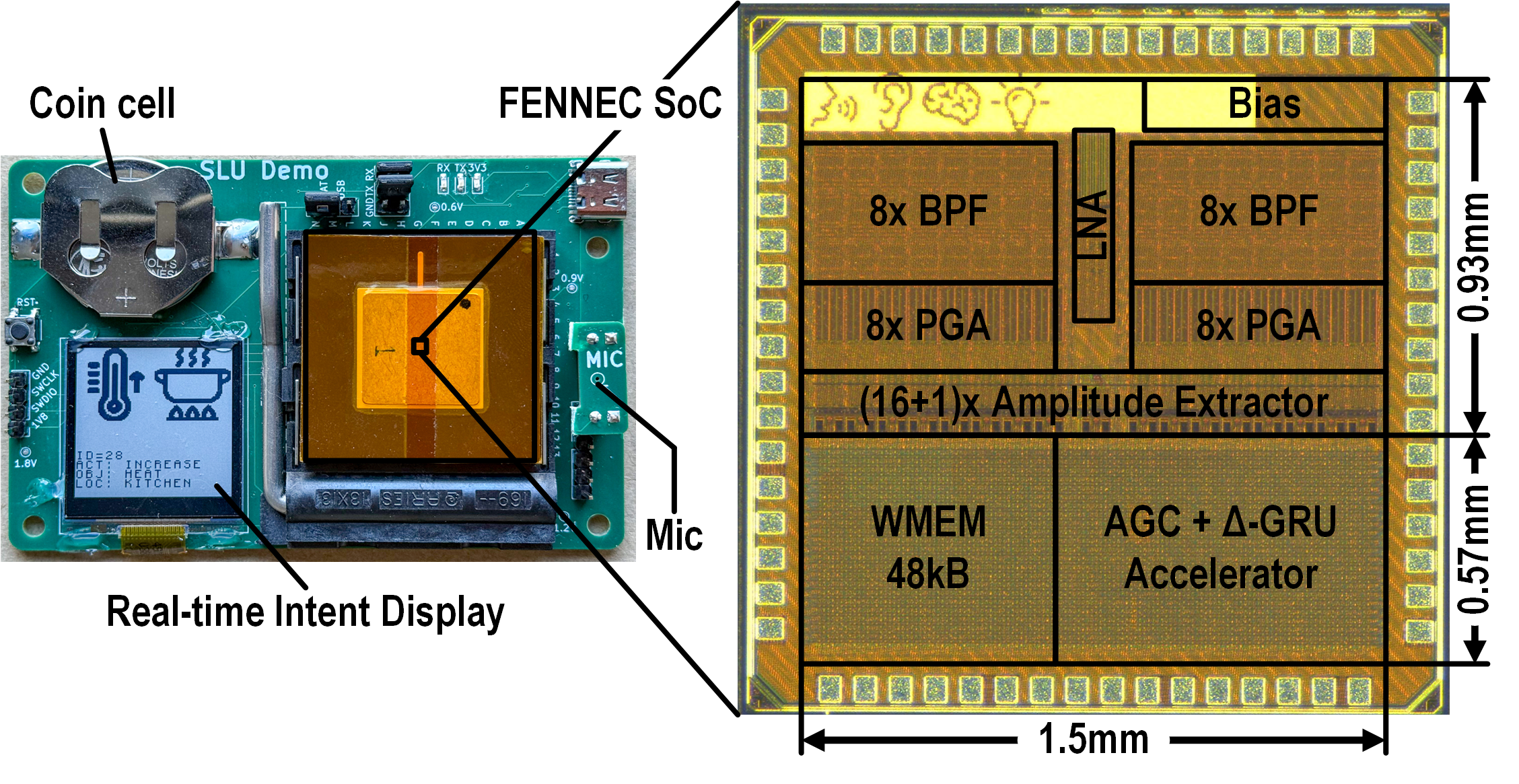 Annotated micrograph of the FENNEC SoC (right) and
Annotated micrograph of the FENNEC SoC (right) and
the complete SLU system powered by a CR2450 coin battery (left).
The AFE and DBE of FENNEC together consume 8.62μW when continuously processing the incoming audio stream. The power breakdown of the SoC is shown in the interactive plot below.
Power breakdown of FENNEC. Click DBE/AFE to zoom in.
The figure below visualizes the measured AFE and DBE outputs for an FSCD sentence
“Turn up the temperature in the kitchen.”
The output features of the AFE clearly show the spectral components of the input audio.
For most of the time, the class with the highest score is <blank>,
which indicates “no user intent detected”.
For a brief moment after an intent sentence is finished,
the class with the highest score becomes the intent class —
in this case, increase + heat + kitchen.
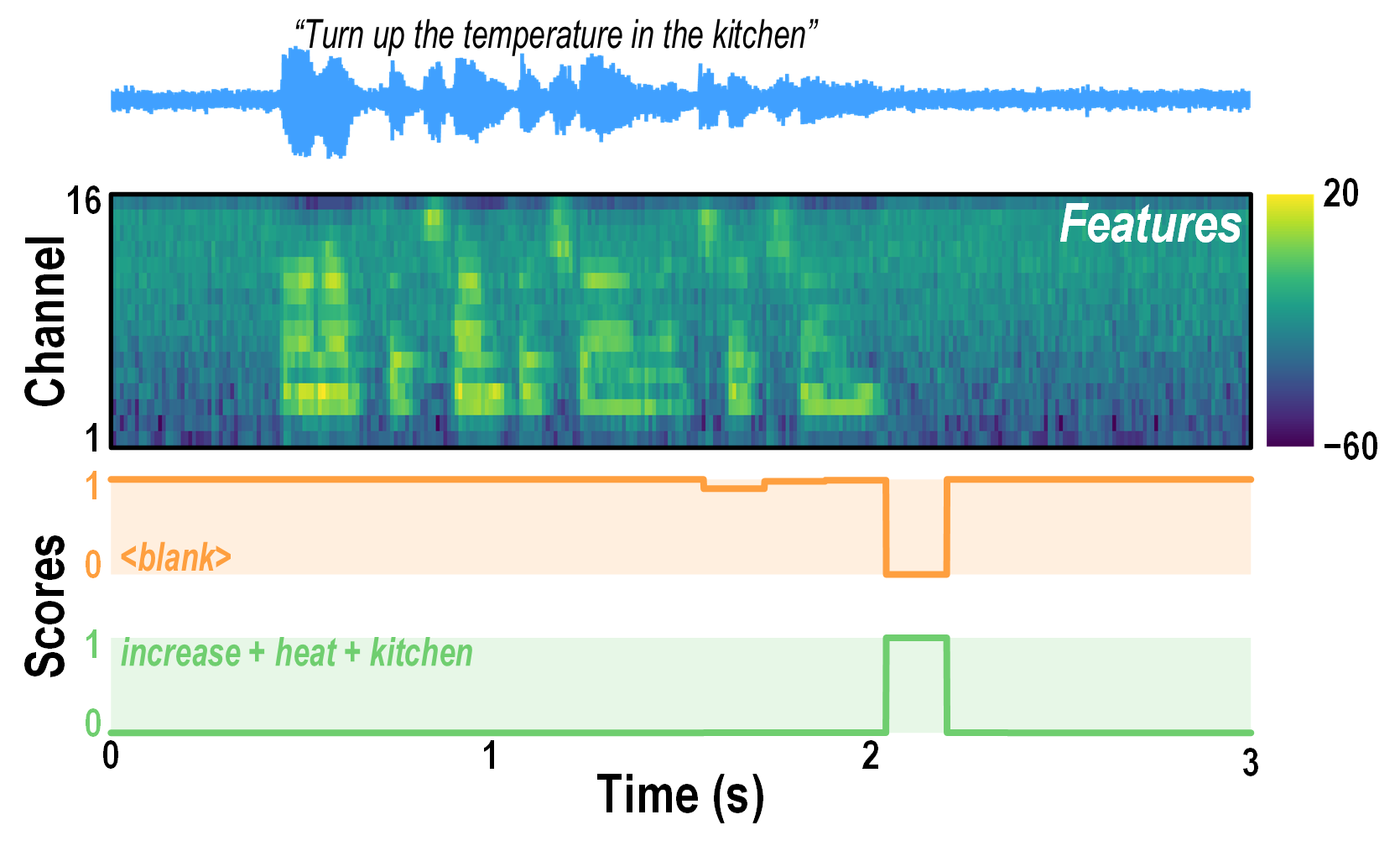 Measured features and output scores for an example sentence from FSCD.
Measured features and output scores for an example sentence from FSCD.
Validating the techniques
AGC
We evaluate FENNEC’s accuracy on FSCD using inputs of different amplitudes.
The SLU task involves 32 classes: 31 user intents plus <blank>.
The highest accuracy of 92.9% is achieved at an input amplitude corresponding to 80dB sound pressure level.
We define the usable DR of the SoC (DRSoC)
as the input range on which >85% SLU accuracy can be achieved.
AGC boosts DRSoC by 41dB.
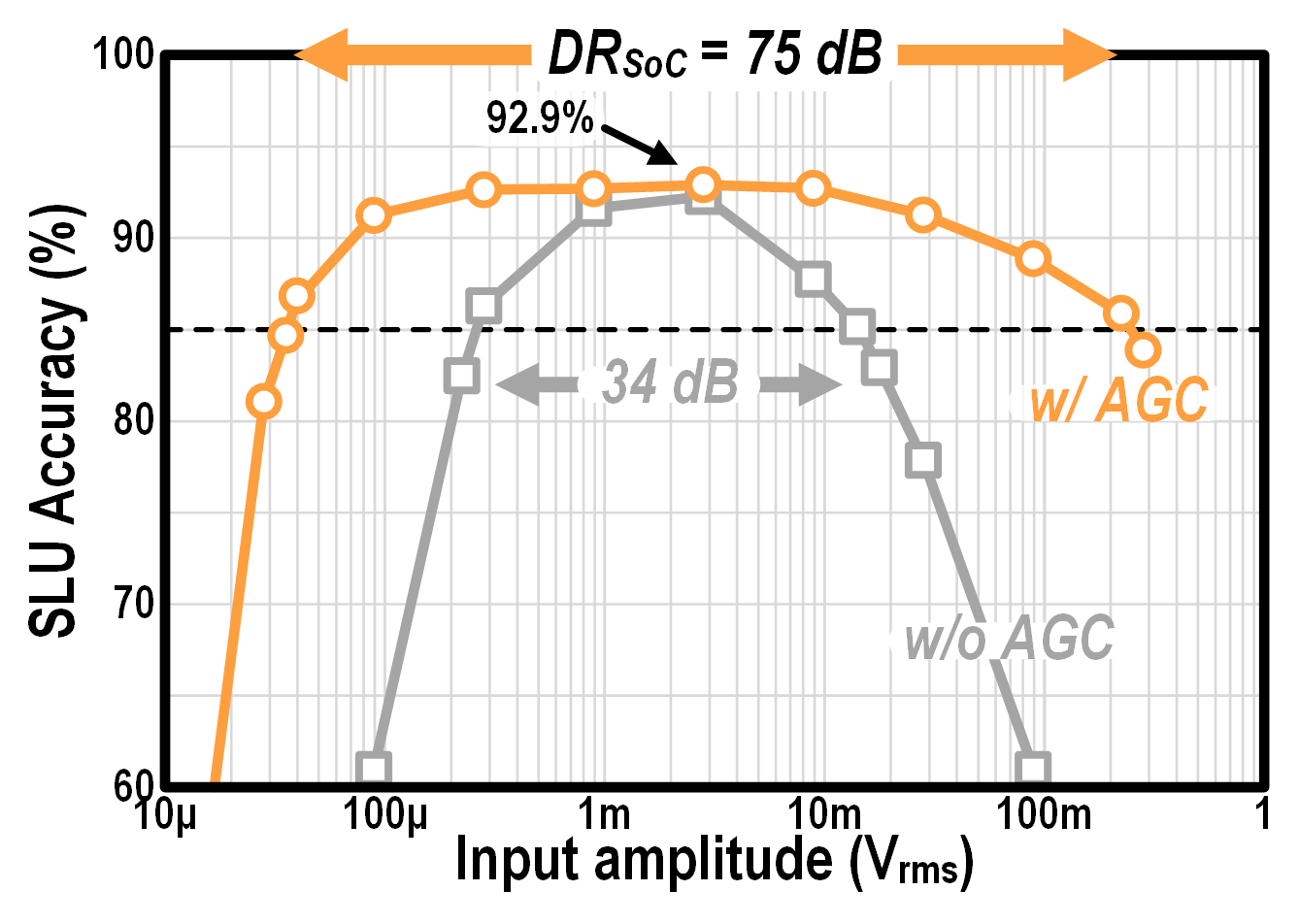 Measured 32-class SLU accuracy on FSCD.
Measured 32-class SLU accuracy on FSCD.
AGC boosts the usable DR of the SoC (DRSoC) from 34dB to 75dB.
HAT
As shown in the table below, without HAT,
SLU accuracy drops by 6.3% due to circuit nonidealities when transfering a model trained on simulated data onto real data from chip measurement.
Using HAT reduces the accuracy drop to 0.7% and boosts the measured SLU accuracy
from 89.7% to 93.1%.
| Train Features
|
HAT
|
Test Set Accuracy (%) | Acc. Drop(%)
|
|
|---|---|---|---|---|
| Simulated | Measured | |||
| Simulated
|
✗ | 96.0 | 89.7 | 6.3 |
| ✓ | 93.1 | 92.4 | 0.7 | |
Δ-GRU
A natural outcome of exploiting temporal sparsity is that power consumption is lower for “boring” inputs such as silence and noise.
This is confirmed by the measured power traces shown below.
In addition, the level of sparsity is tuned by a thresholding parameter Δth that decides which Δ-activation values are skipped.
Increasing Δth leads to higher sparsity and lower power.
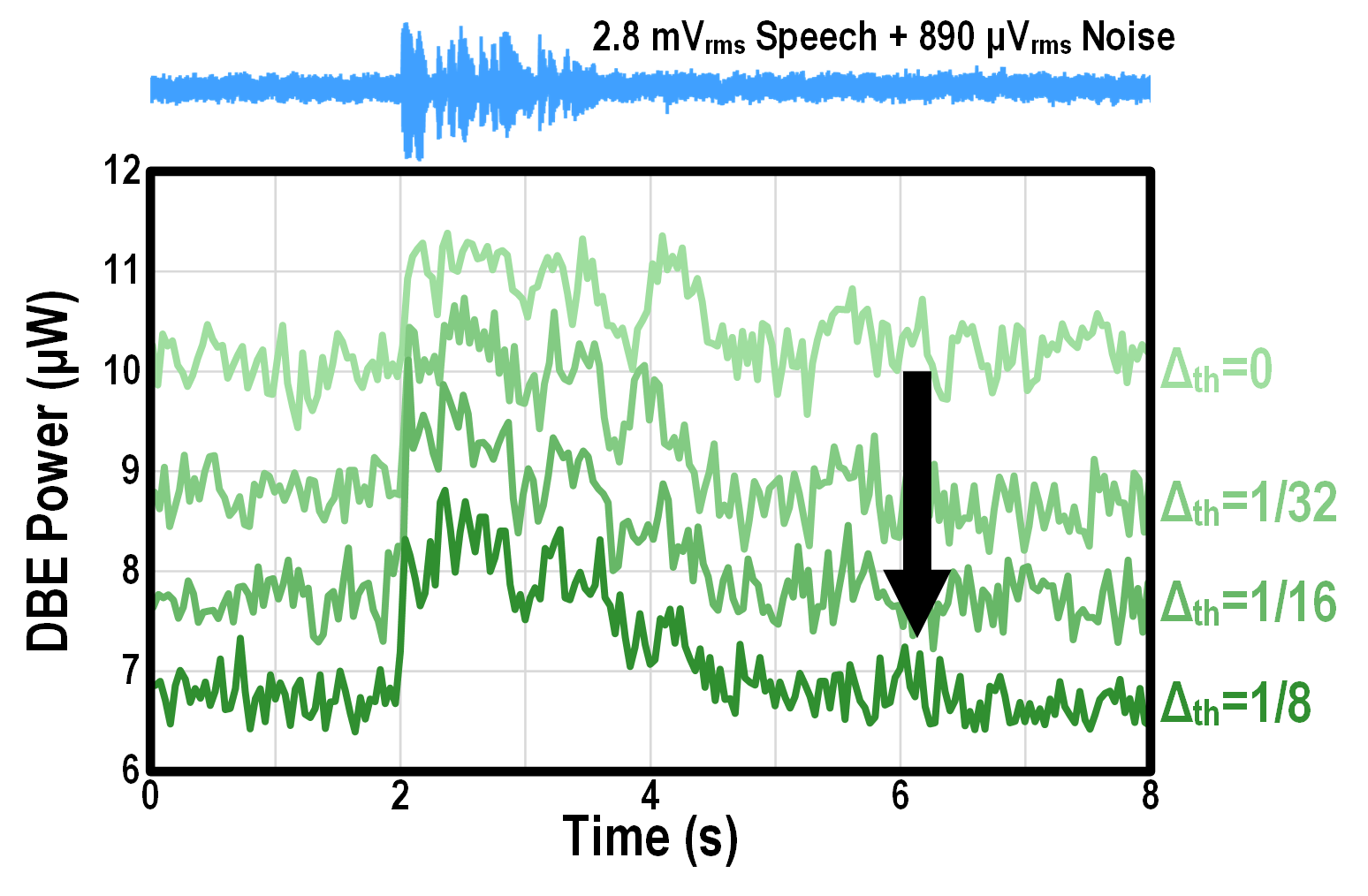 Measured Δ-GRU instantaneous power for a speech sample.
Power consumption
Measured Δ-GRU instantaneous power for a speech sample.
Power consumption
is reduced by increasing the threshold Δth,
and it naturally scales with the input activity.
Comparison with SOTA
The following interactive plot compares state-of-the-art (SOTA) analog acoustic FEx designs in terms of dynamic range (DRAFE), normalized energy per feature (ENORM), as well as Schreier figure of merit (FoMS) which combines the first two. Thanks to AGC, FENNEC’s FEx achieves the best DRAFE (93dB) and FoMS (169.3dB), which are 38dB and 44dB higher than prior SOTA.
Comparison of state-of-the-art analog acoustic FEx designs.
FENNEC achieves the highest AFE dynamic range (DRAFE) and Schreier figure of merit (FoMS).
Comparing with SOTA ultra-low-power speech processing SoC, FENNEC is the first design successully demonstrating 32-class SLU with sentence-level context while consuming single-digit microwatt power. Besides, it achieves competitive task accuracy over a wide DR, a critical requirement for real-world deployment that has been overlooked by previous works. Thanks to HAT, it is also the first work using analog FEx for complex tasks with >15 classes while still achieving >90% accuracy.
| Unit | Wang JSSC’25 |
Yang JSSC’24 |
Giraldo JSSC’20 |
Kim JSSC’22 |
Tan JSSC’25 |
Park VLSI’24 |
FENNEC | |
|---|---|---|---|---|---|---|---|---|
| Speech Task | – | KWS | KWS | KWS | KWS | KWS | KWS | SLU |
| Context Length | – | Word | Word | Word | Word | Word | Word | Sentence |
| #Classes | – | 5 | 7 | 12 | 12 | 12 | 12 | 32 |
| FEx | – | Analog | Digital | Digital | Analog | CNN | Digital | Analog |
| Algorithm | – | SNN | Skip GRU | LSTM | GRU | CNN | CNN | Δ-GRU |
| Process | nm | 65 | 28 | 65 | 65 | 28 | 65 | 65 |
| Memory | kB | 8.2 | 18 | 105 | 27 | 16 | 5 | 48 |
| Area | mm2 | 2.71 | 0.8 | 2.56 | 2.03 | 0.12 | 1.32 | 2.23 |
| Accuracy | % | 90.2 | 92.8 | 90.9 | 86.0 | 91.8 | 92.7 | 92.9 |
| DRSoC | dB | – | – | – | – | – | – | 75 |
| FEx Power | μW | 0.11 | 0.77 | 8.98 | 13 | – | – | 1.85 |
| DNN Power | μW | 0.46 | 0.71 | 3.37 | 10 | – | – | 6.77 |
| Total Power | μW | 0.57 | 1.48 | 16.1 | 23 | 1.73 | 5.6 | 8.62 |
Related works
FENNEC is built upon a series of hardware-software co-design works at Sensors Group for energy-efficient perception on edge devices using bio-inspired principles. The overall design is heavily influenced by CochClass, the first KWS IC with scaling-friendly ring-oscillator-based time-domain FEx. The AFE design can be traced back to silicon cochleae such as CochLP and DAS. The concept of temporal sparsity employed by the DBE is pioneered by the Delta Network, and different versions of hardware design have been iterated on both FPGAs (DeltaRNN, EdgeDRNN, and Spartus) and ASICs (DeltaKWS).
Citation
If you find our work useful, please consider citing our papers.
Conference publication in ISSCC 2025:
@inproceedings{2025-ISSCC-Zhou-SLU,
author={Zhou, Sheng and Li, Zixiao and Delbruck, Tobi and Kim, Kwantae and Liu, Shih-Chii},
booktitle={2025 IEEE International Solid-State Circuits Conference (ISSCC)},
title={An 8.62{μW} {75dB-DR\textsubscript{SoC}} End-to-End Spoken-Language-Understanding {SoC} With Channel-Level {AGC} and Temporal-Sparsity-Aware Streaming-Mode {RNN}},
year={2025},
volume={68},
number={},
pages={238-240},
doi={10.1109/ISSCC49661.2025.10904788}
}
Invited journal extension in JSSC 2025:
@article{2025-JSSC-Zhou-SLU,
author={Zhou, Sheng and Li, Zixiao and Cheng, Longbiao and Hadorn, Jérôme and Gao, Chang and Chen, Qinyu and Delbruck, Tobi and Kim, Kwantae and Liu, Shih-Chii},
journal={IEEE Journal of Solid-State Circuits},
title={An {8.62-μW} {75-dB} {DR\textsubscript{SoC}} Fully Integrated {SoC} for Spoken Language Understanding},
year={2025},
volume={},
number={},
pages={1-16},
doi={10.1109/JSSC.2025.3602936}
}